Welcome! * Добро Пожаловать!
| Обо мне | Мои проекты | Резюме | Стихи | Рассказы | Статьи | Скачать | Ссылки |
|---|
Типичные ошибки программирования на C#
или когда код выглядит верно, но не работает.
Данная статья посвящена анализу наиболее часто встречающихся ошибок в C#-коде, и написана на основе двухлетнего опыта разработки ПО для обнаружения и анализа нефтяных пятен на поверхности воды. Все упомянутые в статье ошибки описаны в литературе; соответственно статья представляет собой нечто вроде проверочного списка или сборника типичных анти-паттернов, основанного на практическом опыте.
-
ЗНАЧИТЕЛЬНАЯ ПОТЕРЯ ТОЧНОСТИ ПРИ ЦЕЛОЧИСЛЕННОМ ДЕЛЕНИИ.
-
Проблема
Согласно правилам преобразования типов C#, при делении целого числа на целое мы получаем в ответе целое число. Таким образом, прямое перенесение математических формул в текст программы даёт некорректные результаты.
-
Примеры
Например, рассмотрим задачу, в которой необходимо вычислить точку пересечения прямой и оси Y, при том что прямая задана двумя точками.
Несложно вывести формулу для Y-координаты:
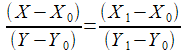 ,
,
откуда
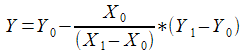
и соответствующая строчка в программе:
double y=y0-x0/(x1-x0)*(y1-y0);
Если мы проведём прямую через точки (1,1) и (4,4) мы вправе
ожидать, что формула вернёт нам 0, так как прямая проходит через
начало координат. К сожалению, вывод программы - в полном согласии
с правилами приведения типов C#! - вернёт нам 0 только в том
случае, если все переменные в левой части объявлены как
тип с плавающей или фиксированной точкой (на самом деле достаточно, чтобы так была объявлена хоть одна из переменных, участвующих в операции деления, а именно x1 или x0); иначе мы получим 1.
Ещё одна задача, приводящая к подобной ошибке - это задача о проекции диапазона. Допустим, у нас есть два диапазона, задаваемых целыми числами [A..B] и [C..D], и значение x1 из первого диапазона. Предполагая, что начало и конец диапазонов в некотором смысле соответствуют друг другу, найдём точку x2, которая соответствует точке x1 в этом же смысле:
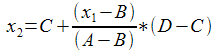 .
.
При прямой подстановке формулы в программу мы для всех точек из диапазона [A..B] в качестве ответа получим точку С, т.к. второе слагаемое при целочисленных переменных - всегда 0.
-
Решение
Хорошим решением было бы, если бы компилятор выдавал предупреждение при возможной потере точности результата при целочисленном делении. К сожалению, в этом случае компилятор C# нас не предупреждает.
Если задачи такого плана типичны - можно написать отдельную функцию, выполняющую операции с числами с плавающей точкой, и возвращающую (при необходимости) округлённый результат.
Наличие в программе выражения с параметрами, по смыслу похожими на целые, включающего операции умножения и деления, но не включаего операции преобразования типов, должно зажигать "красный сигнал" и вызывать желание проверить выражение на отсутствие потери точности. Возможно, стоит предложить JetBrains включить это предупреждение в следующий ReSharper?
-
СПУТАННЫЕ ЕДИНИЦЫ ИЗМЕРЕНИЯ.
-
Проблема
Единицы, в которых - как Вы предполагаете! - измеряется некая величина, не имею ничего общего с теми значениями, которые там в действительности хранятся.
Проблема может возникать вне зависимости от Вашей аккуратности, т.к. данные могут приходит из внешнего источника (файл, база данных, измерительный прибор), при этом документация к форматам данных может отсутствовать или быть неполной/некорректной.
-
Примеры
Для примера рассмотрим следующую строчку (легко заметить, что правила хорошего стиля нарушены - это сделано нарочно для большей наглядности):
double widthInMeters = height * Math.Tan(alpha);
Здесь мы неявно предполагаем, что высота у нас измеряется в метрах, а угол - в радианах. Если хоть одно из этих предположений нарушено (например, кто-то передаёт высоту в пикселях, а углы - в градусах) - у нас проблемы!
-
Решение
Эта проблема более относится к стилю программирования, нежели к проблемам компилятора; поэтому и простые решения здесь отсутствуют. Тем не менее, кое-что сделать всё-таки можно.
-
Если задача позволяет, введите доменные типы (для величин типа длины, скорости, углов и т.п.) - и позвольте этим доменным типам каким-то образом определять, в каких единицах они измерены (либо по одному подтипу для каждой единицы, либо снабжать величины единицами как тегами). Если ещё и описать неявные функции конвертации одних единиц измерения в другие - считайте, что проблема решена. К сожалению, за всё приходится чем-то платить - в данном случае за удобство мы платим скоростью, ибо встроенные оптимизации не будут работать для наших доменных типов.
-
К названию переменных можно добавить единицы измерения (heightInMeters, alphaInRadians, speedInKnots). Тогда присваивания типа heightInMeters = widthInPixels + 2 будут выглядеть достаточно дико, чтобы привлекать внимание.
-
Комментируйте, комментируйте и комментируйте! По крайней мере, если в комментарии написать, что значения углов хранятся в градусах - через две недели не нужно будет гадать, в чём именно хотели углы измерять и будет возможно свести концы с концами.
-
НЕВНЯТНО НАЗВАННЫЕ ФУНКЦИИ.
-
Проблема
По названию функции невозможно определить, что является её результатом, а что - параметром. Проблема ещё более усугубляется, если определены две взаимодополняющие функции с невнятными названиями.
-
Примеры
Пример "по мотивам" реального кода:
class DataObject
{
int GetVerticalAngleRowNumber(int value)
{
//do something, using exemplar values
return result;
}
int GetRowNumberVerticalAngle(int value)
{
//do something, using exemplar values
return result;
}
}
int number = dataObject.GetVerticalAngleRowNumber(alpha);
int angle = dataObject.GetRowNumberVerticalAngle(number);
Вышеприведенные строчки выглядят абсолютно нормально; даже имена функций похожи на хорошие - Camel Case, английские глаголы и существительные…
К сожалению, как выяснилось, порядок слов не стопроцентно определял смысл - так что тот, кто писал функции и тот, кто их вызывал, использовали диаметрально противоположные трактовки (так, первая функция на самом деле принимала номер ряда и возвращала угол).
-
Решение
Называйте функции настолько внятно, чтобы не было возможности понять Вас неправильно. Так, функции из примера были в итоге переименованы в GetRowNumberByVerticalAngle и GetVerticalAngleByRowNumber, что устранило путаницу.
Вот как стал выглядеть код:
class DataObject
{
int GetVerticalAngleByRowNumber(int valuerowNumber)
{
//do something, using exemplar values
return result;
}
int GetRowNumberByVerticalAngle(int valueverticalAngle)
{
//do something, using exemplar values
return result;
}
}
int number = dataObject.GetRowNumberByVerticalAngle(alpha);
int alpha = dataObject.GetVerticalAngleByRowNumber(number);
Также следует заметить, что использование доменных типов данных (и вообще разных типов для номеров и углов) эффективно выявило бы ошибку на этапе компиляции.
-
RACE CONDITIONS.
-
Проблема
Одновременный доступ к одной переменной из разных потоков приводит к непредсказуемому результату.
-
Примеры
Рассмотрим следующий код:
if (instance != null)
{
//do whatever
//...
instance.member = 1;
}
Где вместо //do whatever
помещены действия, занимающие какое-то время. Вроде
бы всё правильно, но… если в какой-то момент программа вываливается
с ошибкой «NullReference Exception» - значит, пока мы были в полной
уверенности, что все предусловия соблюдены, другой поток переписал
переменную, к которой мы обращаемся.
Коварство Race Conditions состоит в том, что ошибка проявляется не всегда - она может проявляться только в определённое время или на определённом компьютере.
Вместо NullReference Вам может встретиться ArrayOutOfBounds, если в качестве предусловия проверяется длина массива, и т.п.
-
Решение
«Каждый, кто собирается работать с потоками, должен чётко знать, что он делает» - звучит хорошо, но не всегда выполнимо, также как и совет писать только потокобезопасные функции.
Тем не менее, к этому стоит стремиться - но если не можешь избежать потоконебезопасности, весь код, содержащий побочные эффекты, следует помещать внутрь критической секции.
-
(ANTI)Patterns
Race Conditions - достаточно хорошо описанный в литературе антипаттерн.
-
ПРОВЕРКА НЕ ТОГО ЭЛЕМЕНТА.
-
Проблема
Несколько раз обращаясь к элементу массива (особенно многомерного, и/или со сложной адресацией) в пределах нескольких строчек, очень легко не заметить, что одно из обращений набрано с ошибкой.
-
Примеры
Пример написан по мотивам реального кода:
//Проходим по квадратному массиву данных и отрисовываем его на экране.
//Следует помнить, что ось Y на экране направлена вниз,
//так что индекс y отсчитывается с конца массива
for(int x=0; x<length; x++)
{
for(int y=0; y<length; y++)
{
if (data[length - y - 1, x] < value1)
{
color = color1;
}
else
if (data[length - y - 1, x] > value2)
{
color = color2;
}
else
{
color = color1 + (int)((double)data[length - x - 1, y] - value1)/(value2 - value1) * (color2 - color1);
}
SetPixelOnScreen(x, y, color);
}
}
Если не присматриваться специально, очень просто не заметить, в чём фокус - в последнем случае при обращении к элементу массива перепутаны индексы. Естественно, этот код не всегда даст правильный результат.
-
Решение
Решение очень простое - достаточно отрефакторить код, введя переменную для анализируемого элемента массива. Поскольку присваивание переменной осуществляется только однажды - глаз "не замыливается" и проверить правильность очень легко.
Вот как выглядит код после исправления:
//Проходим по квадратному массиву данных и отрисовываем его на экране.
//Следует помнить, что ось Y на экране направлена вниз,
//так что индекс y отсчитывается с конца массива
for(int x=0; x<length; x++)
{
for(int y=0; y<length; y++)
{
int element = data[length - y - 1, x];
if (element < value1)
{
color = color1;
}
else
if (element > value2)
{
color = color2;
}
else
{
color = color1 + (int)((double)element- value1)/(value2 - value1) * (color2 - color1);
}
SetPixelOnScreen(x, y, color);
}
}
Д.Булдаков предложил более эффективный и "читабельный" вариант:
//Проходим по квадратному массиву данных и отрисовываем его на экране.
//Следует помнить, что ось Y на экране направлена вниз,
//так что индекс y отсчитывается с конца массива
double fitting = 1/(value2 - value1) * (color2 - color1);
for(int x=0; x<length; x++)
{
for(int y=0, y_data = length-1; y<length; y++, y_data--)
{
int element = data[y_data, x];
if (element < value1)
{
color = color1;
}
else
if (element > value2)
{
color = color2;
}
else
{
color = color1 + (int)((element - value1)*fitting);
}
SetPixelOnScreen(x, y, color);
}
}
-
(ANTI)Patterns
Родственным антипаттерном в данном случае следует признать антипаттерн "Copy-Paste", хотя происхождение данного антипаттерна (по аналогии можно назвать его "Copy-Type") прямо противоположное - перенабрать десяток символов проще, чем скопировать; но и ошибку при перенаборе допустить просто.
Тем не менее, разница между антипаттернами "Copy-Type" и "Copy-Paste" только в происхождении проблемного участка кода; портят жизнь программисту они абсолютно одинаково.
Скачать текст статьи в формате RTF. В архив также включена англоязычная презентация.| Файл изменен 05/11/2007 и просмотрен 51 раз(а). Best viewed in any XHTML/CSS2 capable browser. |